CLV Day: Customer Lifetime Value in the Spotlight
Written by Peter Fader and Daniel McCarthy, Co-founders, Theta | May 2023
May 15 is CLV Day! It’s not an official holiday and has yet to make it on the famous National Day Calendar. (We’re working on that!) However, it is a day that we like to designate for celebrating the use and benefits of customer lifetime value ─ CLV.
But first, why May 15? It has to do with endianness.
From Endianness to Roman Numerals
Endianness describes the order in which a sequence of bytes is stored in computer memory. It can be either big or small, with the adjectives referring to which value is stored first. Endianness also can be used to describe the order in which a date is formatted. For example, May 15, 2023 can be formatted as:
- 15-5-2023 ─ Little-endian date (day, month, year),
- 5-15-2023 ─ Middle-endian dates (month, day, year),
- 2023-5-15 ─ Big-endian date (year, month, day as used in ISO 8601)
Going with just day and month, the little-endian version is 15-5. Writing that as just numerals is 155. In Roman numerals, 155 = CLV. There you have it.
Now for what really matters about CLV: defining it and doing it right.
Getting the Definition and Calculations Wrong
Doing CLV right starts with understanding how easy ─ and common ─ it is to do it wrong. Search the internet for CLV, and you’ll get an abundance of results. Many of them will offer easy formulas for calculating CLV. Most of them will be, well, garbage. The same goes for many of the definitions that are out there for CLV. For example, some companies define CLV as the average historical spend per customer. Others will claim to use some kind of forecast, but they often truncate their calculation of CLV to fit their existing short-term mindset of, say, six- or 12-month projections. Both of these problems will cause companies to undervalue their customers ─ especially those who will likely be around for a long while, i.e., the best customers.
There’s also the matter of how differences across customers play into a CLV calculation. Customers have their own observable or unobservable propensity to churn, to purchase while they are with the firm, and to spend a lot when they buy (i.e., these behaviors are “heterogeneous”). But rather than calculating CLV on an individual or segmented basis, some CLV models calculate an average CLV across the entire customer base. But, as we have said in many other forums, there are no average customers!
Relying too heavily on averages is an issue because the actual values for order frequency and order value can vary significantly from customer to customer. Averaging can’t capture this variation, which is almost always empirically present in data.
The fact is that some customers are more valuable than others. Given that spend is often skewed toward high-value customers (our research shows that typically 65% of revenue comes from just 20% of customers), using an average CLV overestimates low-value customers and underestimates high-value ones.
It’s also common for companies to ignore important dynamics in customer behavior. The problem with that is customers who were good in the past may not necessarily be the best customers in the future. A good CLV model must accurately translate past purchasing dynamics into an accurate prediction of future behavior.
In addition, a lot of the definitions and calculations fail to account for the fact that CLV is fundamentally an estimation of an unknown and not a determination of a known. While you can look at the past revenue total of a customer, estimating the value of a customer over that customer’s lifetime requires a predictive component to account for future purchasing behavior, which naturally comes with uncertainty.
The models used for calculating CLV also matter. Many open-source software packages employ standard probabilistic models built on the Buy Til You Die (BTYD) framework, such as the Pareto-NBD model for repeat purchasing and the Gamma-Gamma model for spend. These models offer good predictive accuracy for straightforward scenarios. But they don’t take into account covariates, such as seasonality, customer lifecycle effects and common demand shocks that can impact a customer’s journey throughout their lifetime with a company and, ultimately, CLV.
It’s easy to see how the simple CLV formulas many companies promote are far too basic to generate useful CLV insights and, in fact, may offer misleading results.

The Theta Approach to CLV
At Theta, we define CLV as an estimate of the total amount of money a company receives from a customer during the entire engagement time before the customer churns. It equals the present value of the cash flows that a customer generates while engaged with the firm minus the cost to acquire the customer, and is used to predict all the value a business will derive from its entire relationship with a customer.
The basic calculation looks like this:
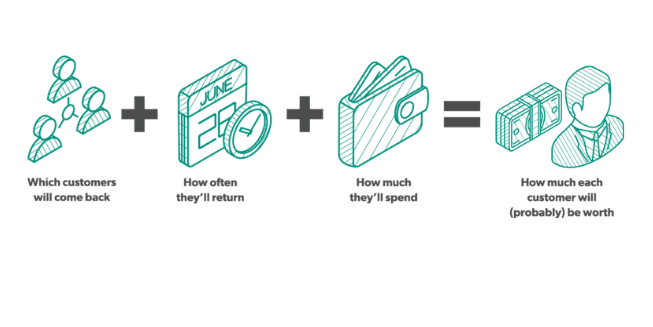
The best model to use to predict these behaviors varies as a function of many things, most important among them being the business model of the firm. We distinguish between contractual and non contractual settings because we know that the nature of customer churn is very different between the two business models.
We also distinguish between the expected lifetime value of an as-yet-to-be acquired customer (or a just-acquired customer) and the expected residual lifetime value of an existing customer. Then there are the previously referenced covariates that we incorporate as necessary. Determining what the relevant covariates are requires a combination of experience (we know what to look for) and working closely with clients to identify the appropriate variables.
The formulas can get complex. But by taking into account the intricacies of customers’ behavior patterns, we’re able to understand the potential variations in behaviors over customers’ lifetimes and predict how they will ultimately affect CLV. This is the key to getting CLV right. For CLV Day, knowing how to get CLV right is a reason to celebrate.